Zgodnie z badaniem Bisnode oraz Dun & Bradstreet, w 2020 r. zarejestrowano w Polsce prawie 12 tys. nowych sklepów internetowych. Ich liczba na początku stycznia 2021 wynosiła w sumie blisko 44,5 tys., o ponad 2% więcej niż rok wcześniej. Dla ich właścicieli – przy braku pewności, czy w kolejnym tygodniu będą mogli otworzyć sklep stacjonarny, czy nie – tym ważniejsza jest pewność funkcjonowania infrastruktury IT. Problem ten dotyczy jednak większości firm działających w obecnej rzeczywistości. Dlatego tak ważne jest nieprzerwane działanie Centrum Danych, w którym funkcjonuje infrastruktura IT, zależne w dużej mierze od zastosowania w nim redundantnych rozwiązań.
Według raportu 2019 Ponemon Institute z roku, średni koszt minuty niezaplanowanej awarii Centrum Danych szacowany jest nawet na 9000 USD. Natomiast maksymalny koszt przestoju przekroczył 2,4 mln USD! W roku 2020 – gdy wszyscy przenieśliśmy naszą działalność do sieci – wartości te zapewne jeszcze się zwiększyły. Poza samą przerwą w działaniu Data Center, szacując straty jego nieplanowanego przestoju należy wziąć pod uwagę także inne czynniki, takie jak utrata zaufania klientów czy wpływ na ceny akcji spółek notowanych na giełdzie.
Redundancja Data Center w skrócie
- W centrach danych znajdują się niezbędne dane biznesowe, więc przerwy w ich działaniu to znaczne koszty, obniżenie produktywności oraz niebezpieczeństwo utraty danych, dlatego w Data Center kluczowe są stabilne działanie i zmniejszenie ryzyka przestojów.
- Niezawodność centrum danych gwarantuje redundancja (nadmiarowość) w trzech kategoriach: ludzi, procesów i wyposażenia (np. zasilania, dostępu do sieci i monitoringu).
- W przypadku zasilania redundancję zapewniają zasilacze awaryjne UPS i generatory.
- Dostępność zwiększa też korzystanie z lokalizacji zapasowej, która w przypadku problemów w głównym centrum danych przejmuje rolę podstawowego ośrodka.
- Ryzyko wystąpienia przestojów minimalizują też systemy monitoringu takich czynników jak: temperatura, wilgotność, dym, napięcie.
- Centrum Danych MAIN jest redundantne w każdej kategorii: personelu, sprawdzonych procesów i infrastruktury. Szczegóły znajdziesz na infografice.
Redundancja w Data Center – czym jest i dlaczego jest tak ważna?
Centra danych odgrywają obecnie główną rolę w przechowywaniu i zabezpieczaniu danych o znaczeniu krytycznym dla prowadzenia działalności biznesowej. Dlatego tak ważne jest dziś ich wydajne i stabilne działanie. Wraz z rosnącą ilością gromadzonych i przechowywanych danych, rosnącymi obawami dotyczącymi zużycia energii, wpływu na środowisko oraz kosztami operacyjnymi związanymi z prowadzeniem Centrum Danych, menedżerowie IT szukają sposobów na uniknięcie dodatkowych kosztów związanych z awariami Data Center. Tym bardziej, że przerwa w jego działaniu ma wpływ nie tylko na budżet firmy. Może ona spowodować uszkodzenie danych organizacyjnych, krytycznego sprzętu podłączonego do Centrum Danych, jak również zmniejszyć produktywności firmy.
Z tych powodów firmy powinny być przygotowane i inicjować strategie mające na celu poprawę dostępności danych oraz zmniejszenie ryzyka przestojów. O niezawodności Centrum Danych decyduje wiele czynników, które można podzielić na trzy grupy: ludzie, procesy i wyposażenie.
Sposobem na zapewnienie niezawodności jest zapewnienie redundancji, czyli dostępu do zapasowych, nadmiarowych komponentów w Centrum Danych.

Zalicza się do nich zasilanie, łączność sieciową, zaawansowane systemy monitoringu, zasilanie awaryjne oraz czujniki wilgoci i ognia.

Dzięki tego typu działaniom zapewniona jest ciągłość działania systemów IT, ale także nieprzerwany dostęp do danych takich, jak spływające na bieżąco zamówienia klientów, stany magazynowe, czy dane finansowo-księgowe.
Jednym ze sposobów zwiększania poziomu dostępności jest też korzystanie z lokalizacji zapasowej, która – w razie potrzeby – przejmuje rolę podstawowego ośrodka. W przypadku niedostępności systemów IT w podstawowym Centrum Danych, następuje przełączenie do lokalizacji zapasowej, która może przejmować funkcje operacyjne również w przypadku planowanych prac konserwacyjnych. Techniki przełączania awaryjnego sprawiają, że systemy stają się odporne na błędy i znacznie poprawia się poziom dostępności. Co istotne, procedura przełączenia powinna odbywać się płynnie, w sposób nieodczuwalny dla użytkowników.
Oprócz wdrożenia komponentów uodparniających na błędy, o wysoki poziom dostępności należy zadbać już na etapie projektu. Wszystkie komponenty Centrum Danych powinny być ocenione pod kątem niezawodności, zaczynając od zrozumienia, jakie metryki są istotne dla poszczególnych komponentów. Przede wszystkim trzeba sprawdzić ograniczenia wydajności i pojemności oraz oczekiwaną żywotność.
Poziomy dostępności infrastruktury IT w zależności od stopnia redundancji:
- 99,67% – brak redundancji stosowanych rozwiązań, niedostępność na poziomie 28,8 godziny w roku
- 99,75% – częściowa redundancja, niedostępność na poziomie 22 godzin w roku
- 99,982% – redundancja N+1, niedostępność na poziomie 1,6 godziny w roku
- 99,995% – redundancja 2N+1, niedostępność na poziomie 0,8 godziny w roku
Źródło – Uptime Institute
Redundancja Data Center na przykładzie MAIN
Redundancja pomaga wyeliminować pojedyncze punkty awarii w obrębie infrastruktury IT. Jednak w każdym przypadku należy odpowiedzieć na pytanie, jaki poziom redundancji jest odpowiedni dla danej firmy. Potrzebna jest więc szczegółowa ocena wymagań.
Rozwiązania zapasowe obejmują, m.in. właściwą konfigurację generatorów oraz zasilaczy awaryjnych UPS. W przypadku generatorów każde urządzenie może zostać zaprogramowane tak, aby uruchamiać się automatycznie w przypadku utraty zewnętrznego zasilania. Tak długo, jak wystarczy paliwa, generator będzie dostarczać energię do Centrum Danych, oczekując na przywrócenie zewnętrznego źródła prądu. W momencie przywrócenia regularnego zasilania generator zatrzyma się.
Aby zminimalizować szansę wystąpienia przestojów, w serwerowni muszą być zainstalowane systemy wykrywania zagrożeń, których zadaniem jest ostrzeganie o problemach, zanim dojdzie do niekorzystnych zdarzeń. Systemy monitoringu i wykrywania mogą śledzić następujące czynniki środowiskowe: temperaturę; wilgotność; przepływ powietrza; napięcie; moc i dym.
 Polecane
Polecane
Sprawdź najpopularniejsze rozwiązania MAIN
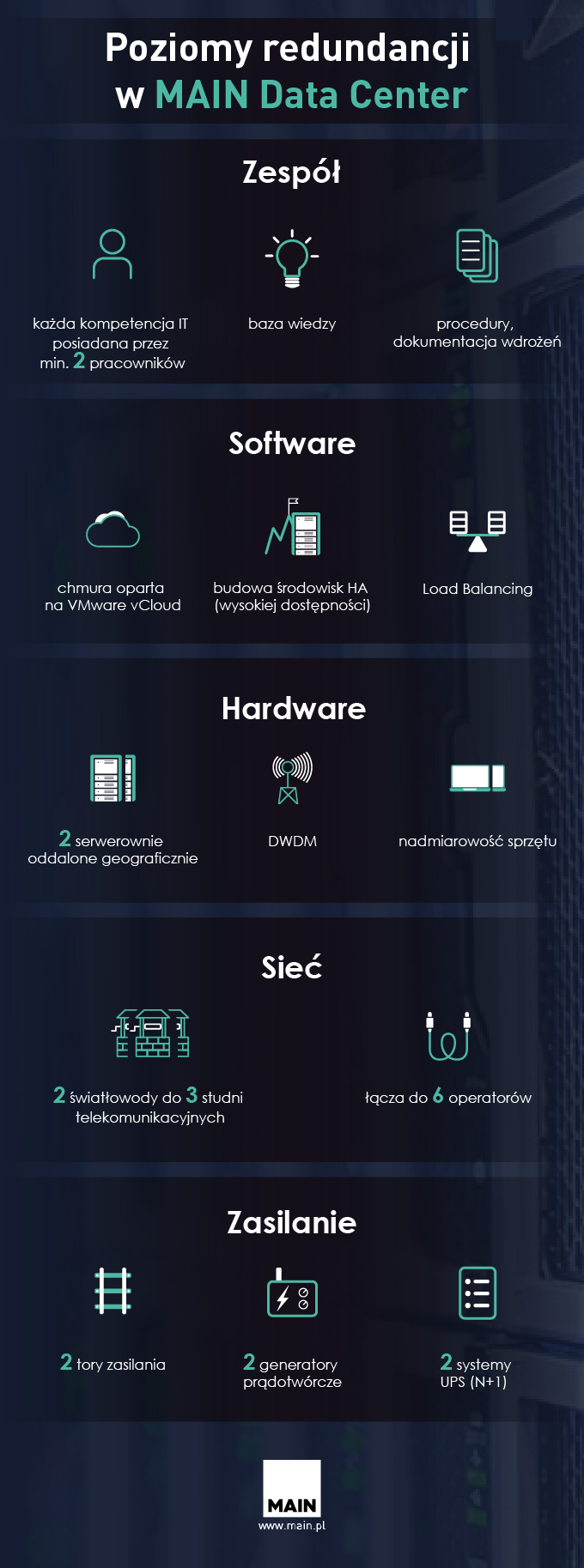
W MAIN Data Center posiadamy
- 2 niezależne tory zasilania z sieci SN 15 kV (1 MW + 1 MW),
- 2 generatory prądotwórcze (450 kVA + 450 kVA) oraz
- 2 modułowe systemy UPS (N+1) pracujące wyłącznie na potrzeby zasilania szaf serwerowych.
Każda szafa rack w naszym Centrum Danych zasilana jest z 2 torów. W przypadku rozwiązań sieciowych dysponujemy łącznikami światłowodowymi do 3 niezależnych studni telekomunikacyjnych i łącza do takich operatorów jak: Orange, Netia, PLIX, Cogent Communications, Star Net Telecom i ETOP.
W samej serwerowni MAIN Data Center działa klaster z zapewnioną odpowiednią nadmiarowością, macierze dyskowe z 2 kontrolerami (co zapobiega ich awarii) oraz RAID-y z nadmiarowymi dyskami. Co ważne korzystamy z dwóch, oddzielonych geograficznie serwerowni, co jest niezmiernie istotne w przypadku usług Disaster Recovery. Połączenie pomiędzy nimi odbywa się dwiema niezależnymi drogami. Posiadamy także własne urządzenia DWDM zapewniające szyfrowanie przesyłanych danych. Dzięki zaś rozwiązaniom VMware, takim jak vCloud, mamy możliwość budowy środowisk High Availability.
Istotne było dla nas także osiągnięcie redundancji w obszarze zespołu IT. Każda czynność techniczna w MAIN Data Center, czy to dotycząca zarządzania chmurą, czy opieki nad sprzętem lub siecią, może więc zostać wykonana przez co najmniej dwóch pracowników. Aby wspierać dzielenie się wiedzą w zespole, zbudowaliśmy m.in. bazę wiedzy dotyczącą czynności administracyjnych na potrzeby utrzymania środowisk poszczególnych klientów. Tworzymy również procedury na każdą czynność wdrożeniową i administracyjną. Dokumentujemy też wszystkie prace wdrożeniowe, co pozwala na wprowadzanie zmian przez innych pracowników zespołu.
Dmuchaj na zimne
Problemy z nieprzerwanym funkcjonowaniem Centrum Danych dotyczą wszystkich, a – jak wspomnieliśmy wcześniej – straty wynikające z jego awarii liczone są w dziesiątkach, a nawet setkach tysięcy dolarów. Powodem często jest brak posiadania redundantnych rozwiązań w Data Center. Przykładowo jedna z najgłośniejszych tego typu awarii w Wells Fargo przełożyła się na stratę ponad 100 000 USD za każdą godzinę jej trwania. Wykryty w Centrum Danych dym spowodował wyłączenie infrastruktury IT, czego skutkiem było pozostawienie klientów tego banku bez możliwości korzystania z kart debetowych i bankowości internetowej. Z kolei w przypadku Delta Airlines straty z powodu nieplanowanego przestoju data center wyniosły aż 150 mln USD. Spowodowało je „uziemienie” na 3 dni ponad 2000 samolotów tej linii lotniczej. Awarie dotykają nawet takich gigantów, jak Google czy Facebook.
Zobacz również
Przejrzyj artykuły
Podczas webinaru przyglądamy się wyzwaniom, takim jak zarządzanie infrastrukturą IT, pokazując, jak podejść do całego procesu strategicznie i świadomie.

Rosnący deficyt doświadczonych specjalistów IT sprawia, że zagrożona jest stabilność infrastruktury IT, zwiększa ryzyko awarii i obniża tempo rozwoju biznesu. Sprawdź, jak organizacje mogą przeciwdziałać tym wyzwaniom.

W 2025 roku Hybrid Cloud i Multicloud to już nie opcja, a standard wymuszony przez regulacje i realia biznesowe. Sprawdź, jak firmy adaptują się do nowych wymagań i co to oznacza dla MŚP.
Chcesz usprawnić sieć w swojej firmie?
Napisz do nas - odpowiemy na wszystkie pytania, zorganizujemy demo i wyjaśnimy, jak Twoja organizacja może skorzystać dzięki SD-WAN.
